

ElasticSearch使用介绍
ES介绍:
ES(Elasticsearch)是一款开源免费的分布式搜索引擎,基于Lucene实现。ES不仅可以进行搜索,还可以对大数据进行分析和存储。ES的使用场景非常广泛,可以用于全文搜索、日志分析、元数据存储等多个领域。
特点: 大数据查询全文检索, 数据统计和分析
1.使用场景:
全文搜索: 可以在新闻网站,电子商务,博客,文章之类的进行快速的搜索,支持基于关键词匹配、词条匹配、短语匹配等多种查询方式。例如,百度,Google,GitHub,Stack Overflow
产品搜索: 电商网站、在线旅游网站等可以将产品信息存储到 Elasticsearch 中,并通过 Elasticsearch 快速地搜索和展示相关产品信息.
日志分析: 可以对系统的运行状况,用户操作行为进行统计和分析,并且还可以进行可视化和数据的监控
元数据存储(描述数据的数据):可以进行各种数据格式的存储,建立索引,可快速找到需要地数据
实时监控: 在电商和金融方面,可以实时监测订单,交易和用户的行为数据,并且对异常事件进行预警和处理,还可以通过可视化界面 进行数据的统计和分析(ES中有多重聚合类型,如bucket(根据字段将数据分组,并单独计算)、metric(对字段进行求和,大小,数量等计算)、pipeline等,将查询结果直接展示出来,不需要额外的计算)
地理信息检索: 在位置和物流方面,可以使用经纬度和坐标对地理位置进行查询和聚合操作. 适用于交通信息,导航和物流配送(ES中提供了一个数据类型 geo_point,这个类型就是用来存储经纬度,提供相应函数做查询)
不合适的方面:
1.es不支持事务和复杂的关系,适合简单的数据量大的查询
2.定义好的字段类型不能修改,如果要修改相当于删表重新建
3.写入数据性能低,资源消耗高,像高并发写入场景,Elasticsearch 在写入大量数据时有较高的延迟,特别是在高并发的情况下。如果应用需要高并发写入数据,可能需要额外的优化措施来降低延迟并保持数据一致性。(有成熟解决方案,配合Logstash使用)
4.没有细致的权限管理,没有像mysql那样的分各种用户,每个用户又有不同的权限。
5.各节点数据的一致性问题,在比较繁忙的集群中,可能会由于网络的阻塞,或者节点处理能力达到饱和,导致各数据节点数据不一致——也就是所谓的脑裂问题,这样会使得集群处于不一致状态。目前并没有一个彻底的方案来解决这个问题,只能通过参数配置和节点角色配置来缓解这种情况(es不适合存放特别重要的数据或者事务性比较强的需求)
6.大文本或二进制数据:Elasticsearch 是一款面向文本的搜索引擎,适合处理文本数据。如果要处理大型的文本或二进制数据,例如视频、图像等,可能需要使用专用的存储和处理系统。
7.数据加密和访问控制:Elasticsearch 提供了基本的安全措施,如 HTTPS 支持、用户名密码认证等,但缺乏细粒度的安全策略和数据加密功能。如果需要更加严格的数据安全控制和加密,可能需要额外的安全措施
es和其他类似产品对比:
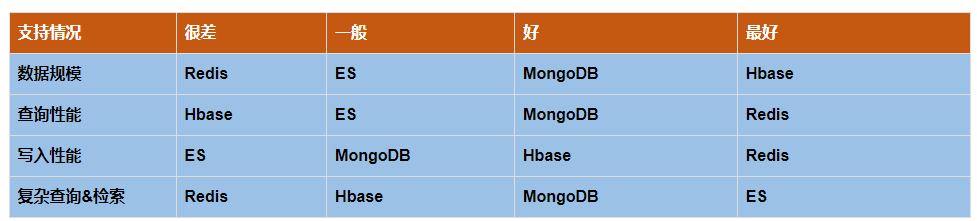
MongoDB更倾向于数据的存储和管理,可以作为数据源对外提供
Elasticsearch更倾向于数据的查询, 一般情况下elasticsearch仅作为数据检索服务和数据分析平台, 不直接作为源数据管理者
- 支持全文检索:Elasticsearch 是一个专门为搜索引擎构建的数据库,支持全文检索和快速查询,而 MongoDB 的文本搜索功能较弱。
- 分布式架构:Elasticsearch 是一个分布式搜索引擎,可以将数据和处理任务分散到多个节点上,能够处理大量的并发读写操作,而 MongoDB 的集群架构相对简单,难以处理大规模的数据处理需求。
- 良好的扩展性:Elasticsearch 的插件生态系统非常丰富,提供了大量的插件和工具,例如 Kibana、Logstash 等,可以为用户提供完整的搜索和分析解决方案,而 MongoDB 的插件生态系统相对较弱。
- 易于使用:Elasticsearch 提供了友好的 RESTful API 接口和丰富的客户端库,支持多种编程语言和平台,易于开发和集成到现有系统中,而 MongoDB 的接口相对较为复杂。
- 数据处理速度更快:Elasticsearch 使用倒排索引来加速搜索,可以快速地定位到包含查询关键字的文档,具有快速、灵活、准确等特点,而 MongoDB 的查询效率相对较低。
2.es的搜索流程
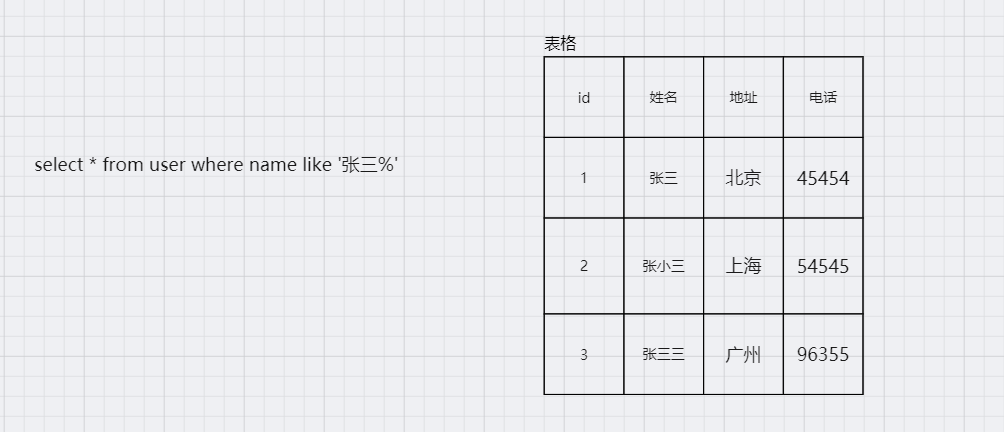
加入有张用户表,通过mysql根据用户名查询用户,但是只能查到张三,和张三三, 查不到张小三,而且使用like导致索引失效进行全表扫描
但是使用es.通过倒排索引就可以查到,然后将id为1,2,3的数据返回
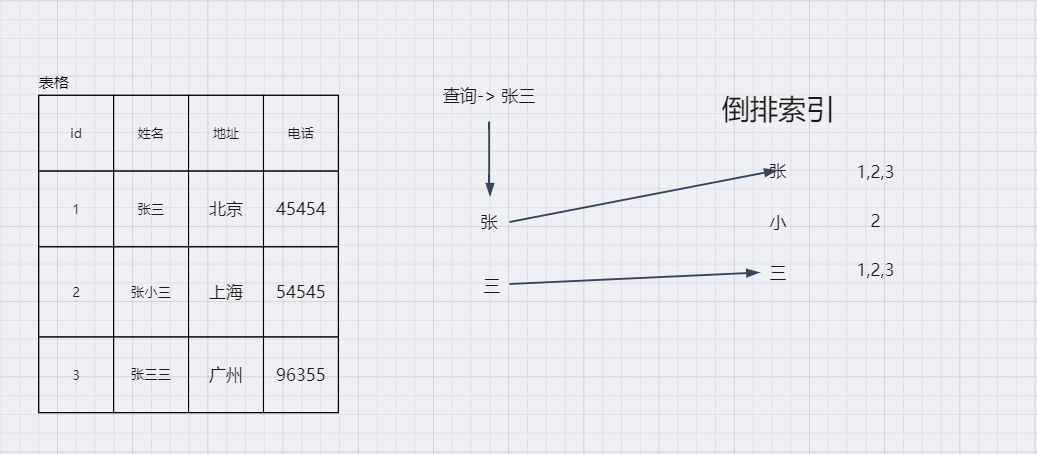
如果这个用数据库的思维来做的话,假如一共100W的记录,按照之前的思路就是扫描100W次,而且每次扫描,都需要匹配那个文本所有的字符,确认是否包含搜索的关键词,而且还不能将搜索词拆解来进行检索
3.es查询快的原因
- 分布式架构设计:Elasticsearch 采用分布式架构,将数据和任务分散到多个节点上,每个节点只负责处理自己的部分数据和查询请求。这样的架构不仅提高了系统的可扩展性,还能极大地加快查询速度。
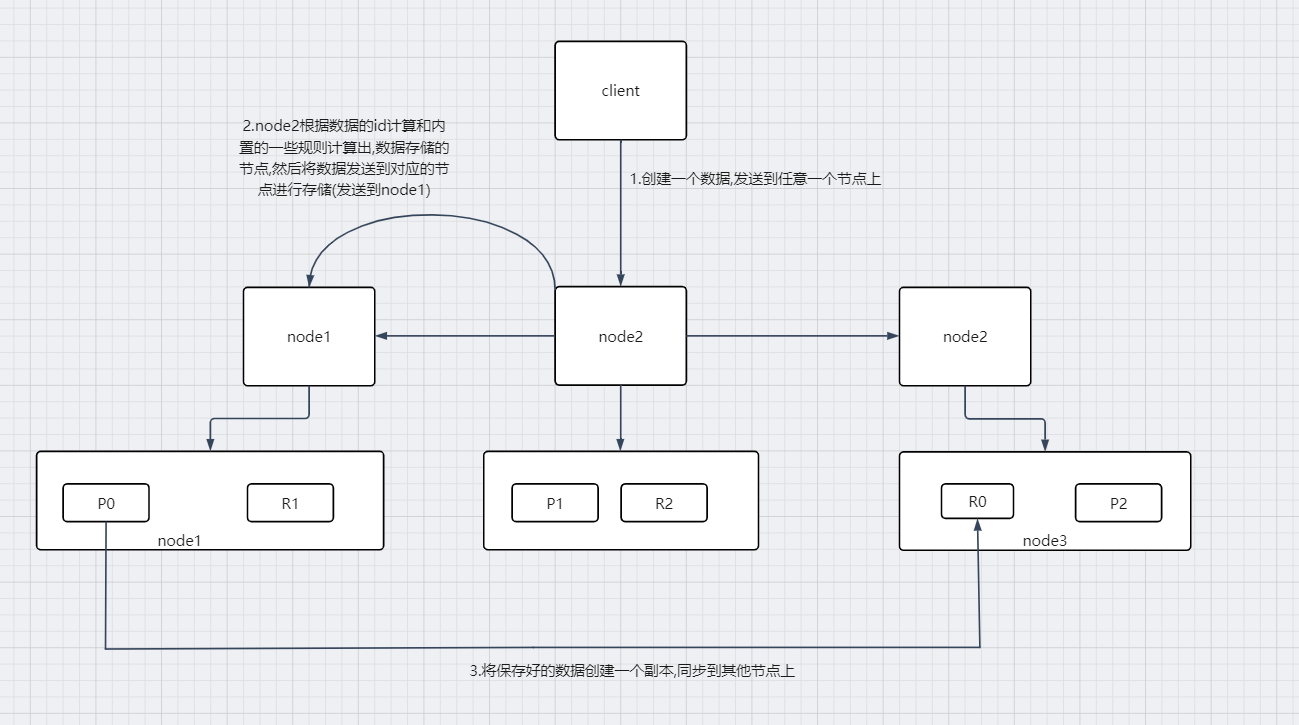
- 倒排索引:Elasticsearch 使用倒排索引的数据结构。这样能快速定位匹配数据,比如匹配某个关键字需要查询的数据,它直接通过词项很快定位到具体的文档列表,而不需要遍历全部文档。
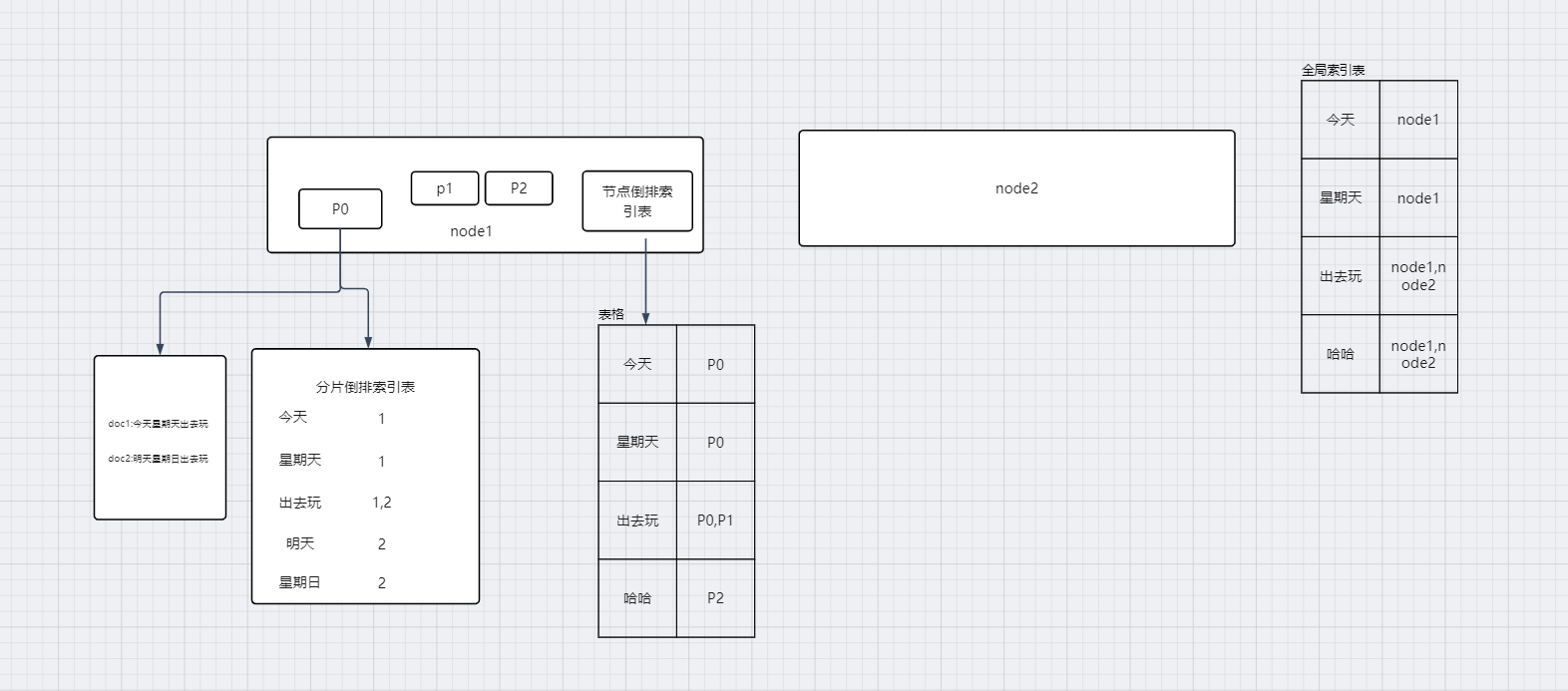
(传统的索引是将文档映射到词条中,查询时需要对所有文档进行扫描,匹配包含查询词条的文档。而倒排索引是将每个词条映射到一组文档中,查询时只需要对包含查询词条的文档进行扫描和匹配,从而大大减少了扫描量,提高了查询效率)
-
缓存机制:Elasticsearch 支持对查询请求的缓存,将查询结果保存在内存中,重复查询相同的请求时,就可以直接从缓存中获取结果,而不需要重新计算,从而极大地提高了查询速度。
-
分片技术:分片技术是 Elasticsearch 的核心功能之一,将一个索引分成多个分片存储在不同的节点上。由于数据分散在多个分片上,每个分片只需要处理自己的数据,能够有效地减轻节点的负载压力,提高查询速度。
-
聚合功能:Elasticsearch 支持强大的聚合(Aggregation)功能,能够在查询同时针对多个字段进行计算和分析,并返回统计结果。聚合查询可以减少网络传输和客户端处理的数据量,从而提高查询速度。
Elasticsearch 使用了基于倒排索引的搜索算法,可以快速地定位到包含查询关键字的文档,并将其返回给用户。其次,它采用了多级缓存机制(如字段数据缓存、过滤器缓存等),可以缓存常用的查询结果,避免反复执行查询造成的性能瓶颈。
此外,在分片合并、去重和排序等操作中,Elasticsearch 还使用了一些高效的算法和数据结构,例如优先队列和归并排序等,来优化复杂的计算过程和减少不必要的开销。同时,它还支持分布式搜索和聚合,这意味着所有的计算工作可以分布在多个节点上进行,大大提高了系统的吞吐量和响应速度。
总之,Elasticsearch 不仅通过优化算法和数据结构,减少搜索的计算量,而且采用了分布式架构和缓存机制等多种手段来提高搜索的效率,保证性能和可扩展性。虽然分片合并、去重和排序等操作会增加一定的成本,但在实际应用中,这些成本通常是可以接受的,因为 Elasticsearch 的搜索效率仍然非常高,并且具有良好的扩展能力。